英伟达H100启用TensorRT-LLM:AI推理性能飙升
|
9月9日消息,英伟达公司今日宣布推出了一项名为TensorRT-LLM的创新项目,旨在大幅提升其Hopper系列AI GPU上的语言模型推理性能。根据英伟达的介绍,TensorRT-LLM是一款深度优化的开源库,利用了一系列尖端技术,包括SmoothQuant、FlashAttention和fMHA等,以加速处理大型语言模型,如GPT-3(175 B)、Llama Falcom(180 B)和Bloom等模型。
据悉,TensorRT-LLM的一个显著特点是引入了一种名为In-Flight Batching的调度方案,这使得GPU能够在处理大型计算密集型请求时,同时动态处理多个较小的查询。这一创新性的方案不仅提高了GPU的性能,还使得H100型号的吞吐量提高了2倍。
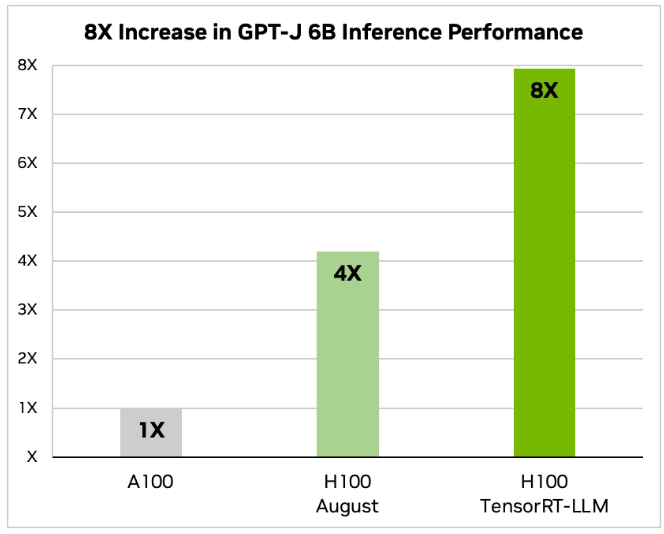
在性能测试方面,英伟达以A100作为基准,对比了H100和启用了TensorRT-LLM的H100。在GPT-J 6B模型的推理性能测试中,H100相比A100提升了4倍,而启用了TensorRT-LLM的H100性能更是达到了A100的8倍。而在Llama 2模型上,H100相比A100提升了2.6倍,而启用了TensorRT-LLM的H100性能则高达A100的4.6倍。
这一重大突破意味着英伟达将继续领导AI硬件领域的发展,通过优化其GPU性能,为大型语言模型等计算密集型任务提供更快速和高效的计算支持。据本站了解,这将对人工智能应用在各个领域的发展产生积极影响,为未来的科技创新打开更广阔的可能性。 |