英伟达 H100 首次亮相 MLPerf,测试结果刷新纪录
|
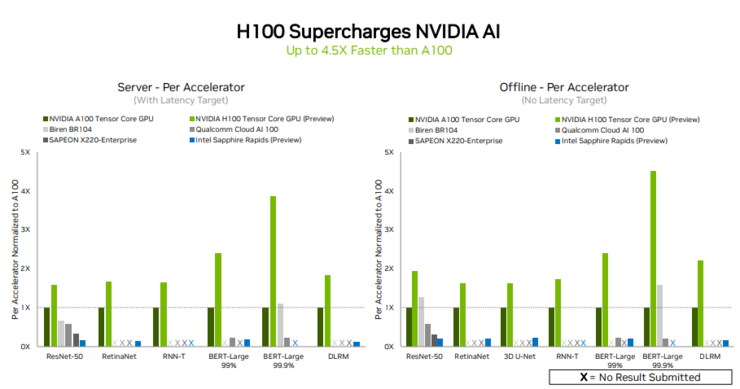
北京时间 9 月 9 日,MLCommons 社区发布了最新的 MLPerf 2.1 基准测试结果,新一轮基准测试拥有近 5300 个性能结果和 2400 个功耗测量结果,分别比上一轮提升了 1.37 倍和 1.09 倍,MLPerf 的适用范围进一步扩大。 阿里巴巴、华硕、Azure、壁仞科技、戴尔、富士通、技嘉、H3C、HPE、浪潮、英特尔、Krai、联想、Moffett、Nettrix、Neural Magic、英伟达、OctoML、高通、SAPEON 和 Supermicro 均是本轮测试的贡献者。 其中,英伟达表现依然亮眼,首次携 H100 参加 MLPerf 测试,并在所有工作负载中刷新世界纪录。 H100 打破世界记录,较 A100 性能提升 4.5 倍 英伟达于今年 3 月份发布基于新架构 NVIDIA Hopper 的 H100 GPU,与两年前推出的 NVIDIA Ampere 架构相比,实现了数量级的性能飞跃。黄仁勋曾在 GTC 2022 上表示,20 个 H100 GPU 便可以承托相当于全球互联网的流量,能够帮助客户推出先进的推荐系统及实时运行数据推理的大型语言模型。 令一众 AI 从业者期待的 H100 原本定于 2022 年第三季度正式发货,目前处于接受预定状态,用户的真实使用情况和 H100 的实际性能尚不可知,因此可以通过最新一轮的 MLPerf 测试得分提前感受 H100 的性能。
在本轮测试中,对比 Intel Sapphire Rapids、Qualcomm Cloud AI 100、Biren BR104、SAPEON X220-enterprise,NVIDIA H100 不仅提交了数据中心所有六个神经网络模型的测试成绩,且在单个服务器和离线场景中均展现出吞吐量和速度方面的领先优势。 以 NVIDIA A100 相比,H100 在 MLPerf 模型规模最大且对性能要求最高的模型之一 —— 用于自然语言处理的 BERT 模型中表现出 4.5 倍的性能提升,在其他五个模型中也都有 1 至 3 倍的性能提升。H100 之所以能够在 BERT 模型上表现初出色,主要归功于其 Transformer Engine。 其他同样提交了成绩的产品中,只有 Biren BR104 在离线场景中的 ResNet50 和 BERT-Large 模型下,相比 NVIDIA A100 有一倍多的性能提升,其他提交成绩的产品均未在性能上超越 A100。 而在数据中心和边缘计算类别的场景中,A100 GPU 的测试成绩依然不俗,得益于 NVIDIA AI 软件的不断改进,与 2020 年 7 月首次亮相 MLPerf 相比,A100 GPU 实现了 6 倍的性能提升。 追求 AI 通用性,测试成绩覆盖所有 AI 模型 由于用户在实际应用中通常需要采用许多不同类型的神经网络协同工作,例如一个 AI 应用可能需要理解用户的语音请求、对图像进行分类、提出建议,然后以语音回应,每个步骤都需要用到不同的 AI 模型。
正因如此,MLPerf 基准测试涵盖了包括计算机视觉、自然语言处理、推荐系统、语音识别等流行的 AI 工作负载和场景,以便于确保用户获得可靠且部署灵活的性能。这也意味着,提交的测试成绩覆盖的模型越多,成绩越好,其 AI 能力更加具备通用性。 在此轮测试中,英伟达 AI 依然是唯一能够在数据中心和边缘计算中运行所有 MLPerf 推理工作负载和场景的平台。 在数据中心方面,A100 和 H100 都提交了六个模型测试成绩。 在边缘计算方面,NVIDIA Orin 运行了所有 MLPerf 基准测试,且是所有低功耗系统级芯片中赢得测试最多的芯片。
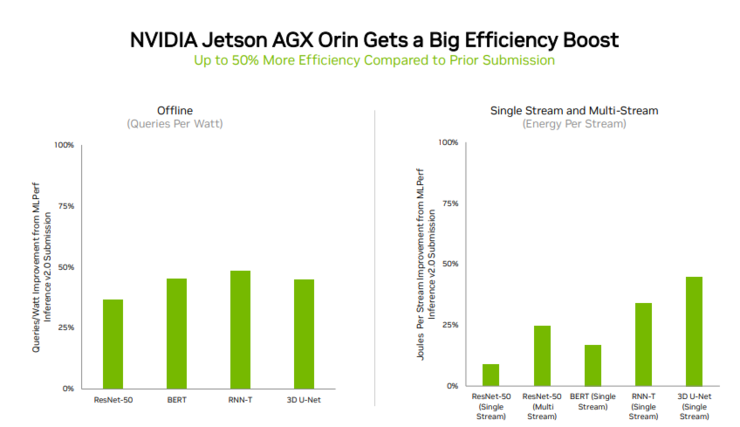
Orin 是将 NVIDIA Ampere 架构 GPU 和 Arm CPU 内核集成到一块芯片中,主要用于机器人、自主机器、医疗机械和其他形式的边缘嵌入式计算。 目前,Orin 已经被用在 NVIDIA Jetson AGX Orin 开发者套件以及机器人和自主系统生成模考,并支持完整的 NVIDIA AI 软件堆栈,包括自动驾驶汽车平台、医疗设备平台和机器人平台。 与 4 月在 MLPerf 上的首次亮相相比,Orin 能效提高了 50%,其运行速度和平均能效分别比上一代 Jetson AGX Xavier 模块高出 5 倍和 2 倍。 追求通用型的 NVIDIA AI 正在被业界广泛的机器学习生态系统支持。在这一轮基准测试中,有超过 70 项提交结果在 NVIDIA 平台上运行。例如,Microsoft Azure 提交了在其云服务上运行 NVIDIA AI 的结果。 |